ここまでの記事で、SpringBatchのバッチ処理の記述の仕方を見てきました。
しかし、ファイルの読み書きばかりでした。
この記事ではDBを扱うサンプルを見てみようと思います。
【処理内容】
まず、これからどのようなことをやろうとしているかを書いておきます。
①ファイルからデータを読み込みます。
②DBのテーブルに読み込んだデータを書き込みます。
【準備】
SpringBatchの準備は今までと同じです。以下の記事を参考に準備をお願いします!
・Spring Batchを使えるようにするには? (準備編)
※DBも作成してください。(サンプルのdataSourceはPostgresになっています)
さらに、今回はデータ書き込み先のテーブルも作っておきます。
<テーブル (使用するDBはPostgeresです)>
CREATE TABLE member
(
id integer NOT NULL,
uname varchar(20),
age integer,
in_date date
)
※他のDBを使用する場合は、DBに合わせてcreate文、dataSourceの設定内容を変更してください。
<パッケージの作成>
プロジェクトには/sample パッケージを作成しておいてください。
【 /sample/back-context.xml ファイル(Batchバックグラウンドの設定)】
以下の記事と同じ物を使いまわします。
リンク内の同じ項目の内容をファイルにしてください。
【SimpleMapFieldSetMapperクラス】
これも前回の記事を使いまわしますので、同じ項目の内容をコピーしてください。
【 /sample/sample-db.txt ファイル(読み込みファイル)】
1,太郎,18
2,次郎,29
3,さんま,53
4,タモリ,54
5,鶴野,28
【 /sample/runDb-context.xml ファイル(バッチ処理の設定)】
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.1.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
">
<import resource="classpath:/sample/back-context.xml"/>
<!-- ジョブの処理 -->
<job id="jobDb" xmlns="http://www.springframework.org/schema/batch
" incrementer="jobParametersIncrementer">
<step id="step1" parent="simpleStep" >
<tasklet >
<chunk reader="fileItemReader" writer="dbItemWriter" commit-interval="2" />
</tasklet>
</step>
</job>
<!-- enables the functionality of JobOperator.startNextInstance(jobName) -->
<bean id="jobParametersIncrementer" class="org.springframework.batch.core.launch.support.RunIdIncrementer" />
<bean id="simpleStep"
class="org.springframework.batch.core.step.item.SimpleStepFactoryBean"
abstract="true">
<property name="jobRepository" ref="jobRepository" />
<property name="startLimit" value="100" />
<property name="commitInterval" value="1" />
</bean>
<!-- ファイルを読み込みMapに入れる -->
<bean id="fileItemReader" class="org.springframework.batch.item.file.FlatFileItemReader" scope="step">
<property name="resource" value="classpath:/sample/sample-db.txt" />
<property name="encoding" value="shift_jis" />
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<property name="names" value="id,uname,age" />
</bean>
</property>
<property name="fieldSetMapper">
<bean class="sample.SimpleMapFieldSetMapper" >
<property name="types" value="int,String,int" />
</bean>
</property>
</bean>
</property>
</bean>
<!-- SQLを実行していく(readしたMapをプレースホルダに設定して実行する)
-->
<bean id="dbItemWriter" class="org.springframework.batch.item.database.JdbcBatchItemWriter">
<property name="dataSource" ref="dataSource" />
<property name="itemSqlParameterSourceProvider">
<bean class="sample.MapSqlParameterSourceProvider" />
</property>
<property name="itemPreparedStatementSetter" >
<bean class="org.springframework.batch.item.database.support.ColumnMapItemPreparedStatementSetter" />
</property>
<property name="sql" value="
insert into member(id, uname, age)
values(:id, :uname, :age)
" />
</bean>
</beans>
【 /sample/MapSqlParameterSourceProvider (SpringJdbc関連のクラス)】
package sample;
import java.util.Map;
import org.springframework.batch.item.database.ItemSqlParameterSourceProvider;
import org.springframework.jdbc.core.namedparam.MapSqlParameterSource;
import org.springframework.jdbc.core.namedparam.SqlParameterSource;
public class MapSqlParameterSourceProvider implements
ItemSqlParameterSourceProvider<Map<String, Object>> {
@Override
public SqlParameterSource createSqlParameterSource(Map<String, Object> map) {
return new MapSqlParameterSource(map);
}
}
【起動方法】
前回までと同じです。
以下のリンクの【実行】と同じことをしてみてください。
ただし、「プログラムの引数」はちょっと変えます。
プログラムの引数 : classpath:/sample/runDb-context.xml jobDb
※ただし、2回目以降は状態がCOMPLETEDになっているため実行エラーが出ます。
この場合、プログラムの引数に -nextを付け加えてみてください。
(参考:・CommandLineJobRunnerとは? )
あと、重複キー違反も起きると思うのでテーブルのデータも一度クリアしてください。
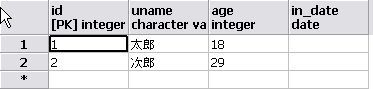
【結果】
2010/08/19 23:29:03.921 [] INFO :: Job: [FlowJob: [name=jobDb]]
launched with the following parameters: [{run.id=1}]
2010/08/19 23:29:04.062 [] INFO :: Executing step: [step1]
2010/08/19 23:29:04.265 [] INFO :: Job: [FlowJob: [name=jobDb]]
completed with the following parameters: [{run.id=1}] and the following status: [COMPLETED]
【説明】
どうでしょうか?
無事、DBにデータが書き込まれましたでしょうか?
やっていることは今までの記事の内容と同じです。
①ItemReaderでファイルからデータを読み込みます。
これは前回の記事、そのままです。
ですので、説明は前回の記事に譲ります。
・Stepを使って処理を書くには?
(作成したクラスSimpleMapFieldSetMapperについて)
②ItemWriterで読み込んだデータを書き込みます。
JdbcBatchItemWriterを使用しています。
再掲:
<bean id="dbItemWriter" class="org.springframework.batch.item.database.JdbcBatchItemWriter">
<property name="dataSource" ref="dataSource" />
<property name="itemSqlParameterSourceProvider">
<bean class="sample.MapSqlParameterSourceProvider" />
</property>
<property name="itemPreparedStatementSetter" >
<bean class="org.springframework.batch.item.database.support.ColumnMapItemPreparedStatementSetter" />
</property>
<property name="sql" value="
insert into member(id, uname, age)
values(:id, :uname, :age)
" />
</bean>
JdbcBatchItemWriterは、SpringJdbcのバッチ機能を使用してDBにアクセスします。
SpringJdbcの詳細は、・SpringJDBCの機能について を参照してください。
SpringJdbcは、"?"をプレースホルダにするタイプと、":名前"をプレースホルダにするタイプがあります。
上記では、後者を使用しています。(sqlプロパティを見てみてください。)
itemSqlParameterSourceProviderは、プレースホルダに使用する値をどのように与えるかを
定義するプロパティです。
ItemReaderは、LinkedHashMapを返すように設定したので、Mapのキー名をプレースホルダに
展開したいのですが、そのようなクラスは既存のSpringBatchでは用意されていません。
ですので、自作しました。(MapSqlParameterSourceProvider)
SpringJdbcのクラスである、MapSqlParameterSourceにMapを渡すだけの単純なクラスです。
本当はMapではなく、Beanを使用すると自作する必要が無いのですが、実験をするときは
やはりメンドウなので、こんなクラスを作っておくと使いまわせますし便利ですよね!
さて、この例で分かったかと思いますが、Spring BatchはSpringJdbcの機能を簡単に扱えます。
バッチ処理をDBで扱う場合、たいていはSQL文の羅列をコマンドでDBに流すことになると思います。
それはそれで分かりやすいし便利ですが、正常に終わらなかったときは事です。
エラーなどで途中で処理が終わった場合、どこまで終わっているのか?、どのような復旧処理をしてから
再実行すればいいのか?、途中から実行できないのか?、など問題点にいとまがありません
SpringBatchでは、処理がどのstepまで終わっているか?などをDBに保存しています。
restartすればDBの値を参考に前回停止したところから処理を再開してくれます。
コマンドでDBに流す場合と同じく、SQL文を書くだけのところは変わらないのに、これだけ違うのです。
すごく便利だと思いません?
【JdbcBatchItemWriterについて】
クラス名に、Batchという言葉が入っています。
Batchというのは、指定の回数だけ一気にデータをDBに送り込むことを示しています。
標準のJavaのJDBCのクラスにもBatchというものがあるので、一般的な機能のようです。
データを一気に送り込むことで、1回1回送り込むよりもDBの処理が早くなります。
バッチ処理を行うときは大量データを送ることが多いと思います。
かなり重宝します!
また、先ほどコマンドでDBに流し込む話をしましたが、その弱点はもう一つあります。
指定の回数だけ一気にデータを送り込んだり、トランザクションのコミットタイミングを制御するのが難しいことです。
SpringBatchを使用すれば、コミットタイミングについても設定だけで可能になります。
コミットタイミングについては別の記事で見てみようと思います。
【その他のORマッピングフレームワーク】
上記ではSpringJDBCを利用できることがわかりました。
では、他のORマッピングについてはどうでしょうか?
他にも使えるものがあります。以下のものです。
・IBatis
・Hibernate
JavaDocを確認してみてください。
また、使えなくても使えるように仲介者クラスを作っておけば大丈夫かと思います。
ここではItemWrtiterしか紹介しませんでしたが、もちろんItemReaderも用意されています。
特に、ページングと言う機能は便利ですので以下で簡単に紹介しておきます。
【ItemReaderのページング機能とは】
簡単にページングについて紹介します。
SpringBatchではページング以外のDB読み込みの機能もありますが、ページングの機能だけで十分ではないかなと思っています。
まあ、とにかく見てみましょう。
例題ではIBatisを使用しますが、他のものでも考え方は同じです。
<bean id="dbReader"
class="org.springframework.batch.item.database.IbatisPagingItemReader">
<property name="queryId" value="getPagingMember" />
<property name="sqlMapClient" ref="sqlMapClient" />
<property name="pageSize" value="70000" />
</bean>
iBatisのSQL文設定ファイル:
<select id="getPagingMember" resultClass="java.util.HashMap">
select
id,
name,
age
from member
order by id asc
offset #_skiprows# LIMIT #_pagesize#
</select>
説明:
ページングとは、WEBのページングのように、ページ番号と1ページのデータ数を指定した検索です。
ページ番号は0~です。
IbatisPagingItemReaderは、#_skiprows#, #_pagesize#さらに、#_page#というパラメタを
自動で設定してくれます。
これらをうまく組み合わせてSQL文で返却するレコードを調整します。
そのPostgresの例題が、上記のSQL文です。
参考までにOracleの例も書いておきます。
Oracleの場合、limitが使えない分やっかいです。
select
id,
name,
age
from (
SELECT row_number() over(order by id) rn,
id,
name,
age
from member
)
where
rn > (#_page# * #_pagesize#)
and rn <= ( (#_page# + 1) * #_pagesize# )
※本家SpringBatchのドキュメントでは、ROW_NUMを使用する方法がかかれていましたが
上記のようにwindow関数を使用する方がきれいかなぁと個人的に思っています。
補足:
ページングは、順番が変わらないフィールドをorder byの対象にすべきだと思います。
処理途中から再実行するときに、再実行までに誰かがデータを増やした場合、順番が変わってしまうと
次に処理するデータが狂ってしまうからです。
たいていの場合、一意のフィールドやシーケンス番号を入れているフィールドなどがあるかと思います。
それらのフィールドを組み合わせれば順番が変わらないようなSQL文も頑張れば作れるでしょう。
さて、大まかですがDBの読み書きについてみてきましたが、分かりましたでしょうか?
いつも分かりやすいか?と自問しながら記事を書いているので、理解できましたらうれしいです
参照:
・データの書き込み(コミット)タイミングを制御するには? (restart機能もついでに見る!)




 (おそらく・・・)
(おそらく・・・)